
What happened before:
In our previous post, we discussed how to gather the necessary data to train your Large Language Model (LLM). My goal is to build a private chatbot based on an LLM without the dependency on public and mostly paying services. We also want all our training data and its results to remain internal for security and privacy reasons.
An additional requirement is that we must be able to run this chatbot on normal general purpose hardware. Sorry NVIDIA, no budget for H100 tensor cores here.. 😋
What is GPT ?
A type of artificial intelligence model based on the Transformer architecture, which was introduced by Vaswani et al. in 2017. The GPT model is designed for natural language processing (NLP) tasks and has seen widespread use in applications like machine translation, text summarization, question-answering, text generation, and more.
The GPT model utilizes a generative approach, which means it can generate human-like text by predicting the next word in a sequence given a context. It is pre-trained on a massive dataset of text and fine-tuned for specific tasks using supervised learning.
So if we want to create an question-answer type chatbot, we definitly need to select a GPT model.
What type of model do we select ?
Many people attempted to develop language models using transformer architecture, and it has been found that a model large enough can give excellent results. However, many of the models developed are proprietary. There are either provided as a service with paid subscription or under a license with certain restrictive terms. Some are even impossible to run on commodity hardware due to is size and high computing demands.
With some Googling, I found that GPT4all could be a suitable solution
GPT4All project tries to make the LLMs available to the public on common hardware. It allows you to train and deploy your model. Pretrained models are also available, with a small size that can reasonably run on a CPU.
So a big advantage is that we can run it on a 'regular' desktop and use a Python library to interact with it.
On the website of GPT4All, there are already different models available, There are also some performance benchmarks available and to get a good balance between size, quality of responses and speed of responses, the model ggml-gpt4all-j-v1.3-groovy.bin looks interesting to start with.
How does it work ? Extend the model with your own data.
Now that we've selected a pretrained model we need to be able to extend it with our own private set of training data
In the context of a language model like GPT-3.5, "embeddings" refer to the representation of words, sentences, or other linguistic units in a continuous vector space. These vector representations capture semantic and syntactic information about the language elements, allowing the model to understand and reason about their meaning.
Embeddings are created through an initial phase of training called "pre-training," where a language model is exposed to a large corpus of text. During pre-training, the model learns to predict the next word in a sentence based on its context. This process helps the model develop an understanding of the relationships between words and their surrounding context.
In the case of GPT-3.5, the model utilizes transformer-based architectures, which incorporate self-attention mechanisms to capture contextual dependencies efficiently. The pre-training process involves optimizing the model's parameters, including the embeddings, to minimize the prediction error. As a result, the model learns to encode meaningful information about words, sentences, and even longer textual sequences into the embedding vectors.
During fine-tuning, the embeddings are typically kept fixed, and only the task-specific layers are trained. By leveraging the pre-trained embeddings, the fine-tuned model benefits from the semantic and syntactic knowledge encoded in the vector representations.
The embeddings must be stored locally in a vector database. This database is then used during the Q&A sequence when talking to the chatbot.

The structure of a private LLM

To begin, let's take a broader perspective on the necessary components for building a local language model capable of interacting with your documents.
Open-source LLM: These are compact open-source alternatives to ChatGPT designed to be executed on your local device. Several well-known examples include Dolly, Vicuna, GPT4All, and llama.cpp. These models undergo extensive training on extensive text datasets, enabling them to generate top-notch responses to user inputs.
Embedding Model: An embedding model is employed to convert textual data into a numerical format, facilitating straightforward comparison with other text data. Usually, this is achieved through the application of word or sentence embeddings, which represent text as compact vectors within a multidimensional space. By utilizing these embeddings, it becomes possible to identify documents that are relevant to the user's input.
Vector Database: A database specifically tailored for vector storage and retrieval is intended for efficient handling of embeddings. It allows storing the content of your documents in a format that enables seamless comparison with user prompts.
Knowledge documents: A compilation of documents comprising the
information that your LLM will utilize to respond to your inquiries. This is the specific content we've brought together from the different training videos, how-to guides, release notes and best practices guides. How to get this data and bring it together in a readble form for the embeddings is described in my previous post.
Bringing this together
Within this project you can select a local model and with the power of LangChain you can run the entire pipeline locally, without any data leaving your environment, and with reasonable performance.
ingest.pyusesLangChaintools to parse the document and create embeddings locally usingLlamaCppEmbeddings.- It then stores the result in a local vector database using
Chromavector store. privateGPT.pyuses a local LLM based onGPT4All-JorLlamaCppto understand questions and create answers. The context for the answers is extracted from the local vector store using a similarity search to locate the right piece of context from the docs.GPT4All-Jwrapper was introduced in LangChain 0.0.162.
To use PrivateGPT, you’ll need Python installed on your computer.
You can start by cloning the PrivateGPT repository on your computer and install the requirements:
git clone https://github.com/SamurAIGPT/EmbedAI.git Go to client folder and run the following commands:
npm installnpm run dev Then go to the server folder and run the following commands:
pip install -r requirements.txtpython privateGPT.py Now the server is running and we can connect to the webinterface:
-
Open http://localhost:3000, click on download model to download the required model initially (you only have to do this once)
- Upload any document of your choice and click on Ingest data. Ingestion is a quite fast process.
In this step, we populate the vector database with the embedding values of the provided documents. Fortunately, the project has a script that performs the entire process of breaking documents into chunks, creating embeddings, and storing them in the vector databas.
You can also dump all your data you want to have ingested in the /server /source documents/ folder. Once you've ingested the data, this folder can be emptied. All the vectors are kept in the database so use this folder only for ingesting new additional information.
-
Now run any query on your data. Data querying is quite slow and it can take some time until an answer is formulated. And then you can start talking to your local LLM. Also nice to see is that there is alway a reference given in the response, so you know from where the data/knowledge came initialy. This means that you should give your source datafiles a human readable and understandable filename that makes sense.
What is the private LLM workflow ?
So before you can use your local LLM, you must make a few preparations:
Create a list of documents that you want to use as your knowledge base
Break large documents into smaller chunks (around 500 words)
Create an embedding for each document chunk
Create a vector database that stores all the embeddings of the documents
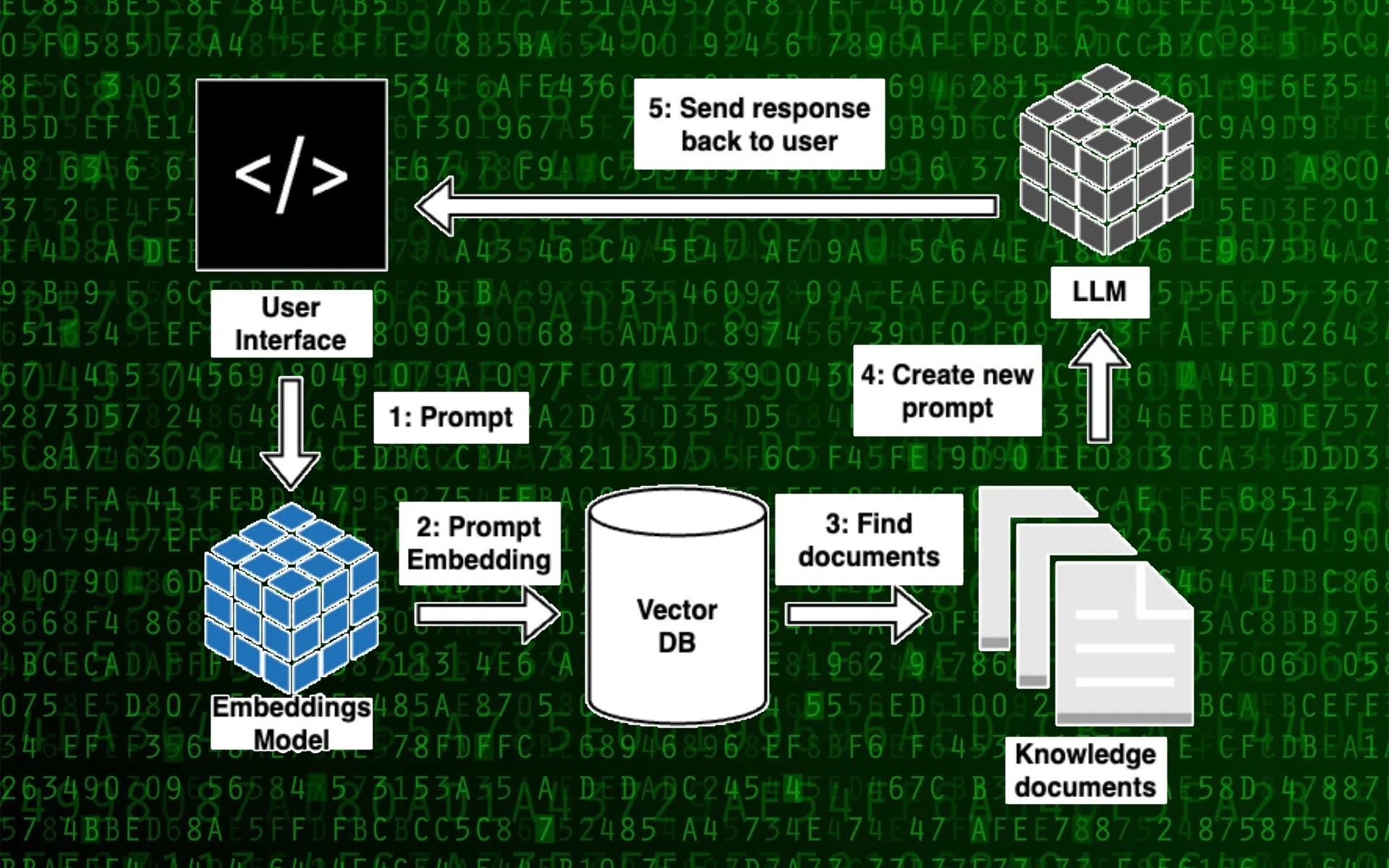
Once this is done, you can start querying the database.
The user enters a prompt in the user interface.
The application uses the embedding model to create an embedding from the user’s prompt and send it to the vector database.
The vector database returns a list of documents that are relevant to the prompt based on the similarity of their embeddings to the user’s prompt.
The application creates a new prompt with the user’s initial prompt and the retrieved documents as context and sends it to the local LLM.
The LLM produces the result along with citations from the context documents. The result is displayed in the user interface along with the sources.
Comparatively, open-source LLMs are more compact than cutting-edge models such as ChatGPT and Bard, and they may not excel in every conceivable task to the same extent. However, when supplemented with your own documents, these language models become highly potent, particularly for tasks like search and question-answering.
Why PrivateGPT ?
By using a local language model and vector database, you can maintain control over your data and ensure privacy while still having access to powerful language processing capabilities.
PrivateGPT includes a language model, an embedding model, a database for document embeddings, and a command-line interface. It supports several types of documents including plain text (.txt), comma-separated values (.csv), Word (.docx and .doc), PDF, Markdown (.md), HTML, Epub, and email files (.eml and .msg).